I recently stumbled on an entry by Lucas Gonze where he complains about the RSS <enclosure> element. He writes
Problems with the enclosure element:
- It causes users to download big files that they will never listen to or watch, creating pointless overload on web hosts.
- It doesn't allow us to credit the MP3 host, so we can't satisfy the netiquette of always linking back.
- For broadband users, MP3s are not big enough to need advance caching in the first place.
- The required content-type attribute is a bad idea in the first place. Mime settings are already prone to breakage, adding an intermediary will just create another source of bugs. There are no usecases for this attribute that can't be more easily and robustly satisfied by having clients HEAD the URL for themselves.
- The required content-length attribute should not be there. It requires people who link to MP3s to HEAD them and calculate the length, which is sometimes not practical. It makes variable-length MP3s illegal. There are no usecases for this attribute that can't be more easily and robustly satisfied by having clients HEAD the URL for themselves.
The primary problem with the <enclosure> element is that it is overspecified. Having an element that says, here is a pointer to some data that is related to this entry that is too large to fit in the feed is a good idea. Similarly providing a hint at what the MIME type is so the reader knows whether it can handle that MIME type or can display something specific to that media type in the user interface without making an additional request to the server is very useful. The description of the enclosure element in RSS 2.0 states
<enclosure> sub-element of <item> 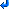
<enclosure> is an optional sub-element of <item>.
It has three required attributes. url says where the enclosure is located, length says how big it is in bytes, and type says what its type is, a standard MIME type.
The url must be an http url.
<enclosure url="http://www.scripting.com/mp3s/weatherReportSuite.mp3" length="12216320" type="audio/mpeg" />
Syndication geeks might notice that this is akin to the <link> element in the ATOM 0.3 syndication format which is described as
3.4 Link Constructs
A Link construct is an element that MUST NOT have any child content, and has the following attributes:
3.4.1 "rel" Attribute
The "rel" attribute indicates the type of relationship that the link represents. Link constructs MUST have a rel attribute, whose value MUST be a string, and MUST be one of the values enumerated in the Atom API specification <eref>http://bitworking.org/projects/atom/draft-gregorio-09.html</eref>.
3.4.2 "type" Attribute
The "type" attribute indicates an advisory media type; it MAY be used as a hint to determine the type of the representation which should be returned when the URI in the href attribute is dereferenced. Note that the type attribute does not override the actual media type returned with the representation.
Link constructs MUST have a type attribute, whose value MUST be a registered media type [RFC2045].
3.4.3 "href" Attribute
The "href" attribute contains the link's URI. Link constructs MUST have a href attribute, whose value MUST be a URI [RFC2396].
xml:base [W3C.REC-xmlbase-20010627] processing MUST be applied to the atom:url element.
3.4.4 "title" Attribute
The "title" attribute conveys human-readable information about the link. Link constructs MAY have a title attribute, whose value MUST be a string.
So the ideas behind the <enclosure> element were good enough that they appear in ATOM with some additional niceties and a troublesome bit (the length attribute) removed. So if the concepts behid the <enclosure> element are so good that they are first class members of the ATOM syndication format. Why does Lucas not like it? The big problem with RSS enclosures is how Dave Winer expected them to be used. An aggregator was supposed to act like a TiVo, automatically downloading files in the background and presenting them to you when it's done. The glaring problem with doing this is that it means lots of people are automatically downloading large files that they didn't request which is a significant waste of bandwidth. In fact, most aggregators either do not support enclosures or simply show them as links which is what FeedDemon and RSS Bandit (with the Outlook 2K3 skin) do. The funny thing is that the actual RSS specification doesn't describe this behavior, instead this behavior is implied by Dave Winer's descriptions of use cases.
Lucas also complains about the required length attribute which is problematic if you are pointing to a file on a server you don't own because you have to first download the file or perform a HTTP HEAD to get its size. The average blogger isn't going to go through that kind of trouble. Although tools could help it makes sense for the length attribute to have been an optional hint.
I have to disagree with Lucas's complaints about putting the MIME type in the <enclosure> element. He complains that the MIME type in the <enclosure> could be wrong and in fact that in many cases web servers serve a file with the wrong MIME type. Thus he concludes that putting the MIME type in the enclosure is wrong. Client software should be able, to decide how to react to the enclosure [e.g. if it is audio/mpeg display a play button] without having to make additional HTTP requests especially since as Lucas points out it is not a 100% guaranteed that performing an HTTP HEAD of the linked file will actually get you the correct MIME type from the web server.
In conclusion, I agree that the <enclosure> element is problematic but most of the problems are due to the implied use case suggested by the spec author, Dave Winer, as opposed to the actual information provided by the element. The ATOM approach of describing the information provided by each element in a feed but not explicitly describing the expected behavior of clients is a welcome approach. Of course, there will always be developers who require structure or take an absence of explicit guidelines to mean do stupid things (like aggregators that fetch your feed every 5 minutes) but these are probably better handled in "Best Practices" style documents or test suites than in the actual specification.