As I've mentioned previously, one of the features we shipped in the most recent release of Windows Live is the ability to import your activities from photo sharing sites like Flickr and PhotoBucket or even blog posts from a regular RSS/Atom feed onto your Windows Live profile. You can see this in action on my Windows Live profile.
One question that has repeatedly come up for our service and others like it, is how users can get a great experience from just importing RSS/Atom feeds of sites that we don't support in a first class way. A couple of weeks ago Dave Winer asked this of FriendFeed in his post FriendFeed and level playing fields where he writes
Consider this screen (click on it to see the detail): 
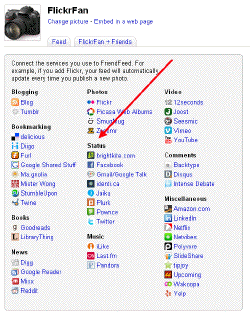
Suppose you used a photo site that wasn't one of the ones listed, but you had an RSS feed for your photos and favorites on that site. What are you supposed to do? I always assumed you should just add the feed under "Blog" but then your readers will start asking why your pictures don't do all the neat things that happen automatically with Flickr, Picasa, SmugMug or Zooomr sites. I have such a site, and I don't want them to do anything special for it, I just want to tell FF that it's a photo site and have all the cool special goodies they have for Flickr kick in automatically.
If you pop up a higher level, you'll see that this is actually contrary to the whole idea of feeds, which were supposed to create a level playing field for the big guys and ordinary people.
We have a similar problem when importing arbitrary RSS/Atom feeds onto a user's profile in Windows Live. For now, we treat each imported RSS feed as a blog entry and assume it has a title and a body that can be used as a summary. This breaks down if you are someone like Kevin Radcliffe who would like to import his Picasa Web albums. At this point we run smack-dab into the fact that there aren't actually consistent standards around how to represent photo albums from photo sharing sites in Atom/RSS feeds.
Let's look at the RSS/Atom feeds from three of the sites that Dave names that aren't natively supported by Windows Live's Web Activities feature.
Picassa
<item>
<guid isPermaLink='false'>http://picasaweb.google.com/data/entry/base/user/bo.so.po.ro.sie/albumid/5280893965532109969/photoid/5280894045331336242?alt=rss&hl=en_US</guid>
<pubDate>Wed, 17 Dec 2008 22:45:59 +0000</pubDate>
<atom:updated>2008-12-17T22:45:59.000Z</atom:updated>
<category domain='http://schemas.google.com/g/2005#kind'>http://schemas.google.com/photos/2007#photo</category>
<title>DSC_0479.JPG</title>
<description><table><tr><td style="padding: 0 5px"><a href="http://picasaweb.google.com/bo.so.po.ro.sie/DosiaIPomaraCze#5280894045331336242"><img style="border:1px solid #5C7FB9" src="http://lh4.ggpht.com/_xRL2P3zJJOw/SUmBJ6RzLDI/AAAAAAAABX8/MkPUBcKqpRY/s288/DSC_0479.JPG" alt="DSC_0479.JPG"/></a></td><td valign="top"><font color="#6B6B6B">Date: </font><font color="#333333">Dec 17, 2008 10:56 AM</font><br/><font color=\"#6B6B6B\">Number of Comments on Photo:</font><font color=\"#333333\">0</font><br/><p><a href="http://picasaweb.google.com/bo.so.po.ro.sie/DosiaIPomaraCze#5280894045331336242"><font color="#3964C2">View Photo</font></a></p></td></tr></table></description>
<enclosure type='image/jpeg' url='http://lh4.ggpht.com/_xRL2P3zJJOw/SUmBJ6RzLDI/AAAAAAAABX8/MkPUBcKqpRY/DSC_0479.JPG' length='0'/>
<link>http://picasaweb.google.com/lh/photo/PORshBK0wdBV0WPl27g_wQ</link>
<media:group>
<media:title type='plain'>DSC_0479.JPG</media:title>
<media:description type='plain'></media:description>
<media:keywords></media:keywords>
<media:content url='http://lh4.ggpht.com/_xRL2P3zJJOw/SUmBJ6RzLDI/AAAAAAAABX8/MkPUBcKqpRY/DSC_0479.JPG' height='1600' width='1074' type='image/jpeg' medium='image'/>
<media:thumbnail url='http://lh4.ggpht.com/_xRL2P3zJJOw/SUmBJ6RzLDI/AAAAAAAABX8/MkPUBcKqpRY/s72/DSC_0479.JPG' height='72' width='49'/>
<media:thumbnail url='http://lh4.ggpht.com/_xRL2P3zJJOw/SUmBJ6RzLDI/AAAAAAAABX8/MkPUBcKqpRY/s144/DSC_0479.JPG' height='144' width='97'/>
<media:thumbnail url='http://lh4.ggpht.com/_xRL2P3zJJOw/SUmBJ6RzLDI/AAAAAAAABX8/MkPUBcKqpRY/s288/DSC_0479.JPG' height='288' width='194'/>
<media:credit>Joanna</media:credit>
</media:group>
</item>
Smugmug
<entry>
<title>Verbeast's photo</title>
<link rel="alternate" type="text/html" href="http://verbeast.smugmug.com/gallery/5811621_NELr7#439421133_qFtZ5"/>
<content type="html"><p><a href="http://verbeast.smugmug.com">Verbeast</a> </p><a href="http://verbeast.smugmug.com/gallery/5811621_NELr7#439421133_qFtZ5" title="Verbeast's photo"><img src="http://verbeast.smugmug.com/photos/439421133_qFtZ5-Th.jpg" width="150" height="150" alt="Verbeast's photo" title="Verbeast's photo" style="border: 1px solid #000000;" /></a></content>
<updated>2008-12-18T22:51:58Z</updated>
<author>
<name>Verbeast</name>
<uri>http://verbeast.smugmug.com</uri>
</author>
<id>http://verbeast.smugmug.com/photos/439421133_qFtZ5-Th.jpg</id>
<exif:DateTimeOriginal>2008-12-12 18:37:17</exif:DateTimeOriginal>
</entry>
Zooomr
<item>
<title>ギンガメアジとジンベイ</title>
<link>http://www.zooomr.com/photos/chuchu/6556014/</link>
<description>
<a href="http://www.zooomr.com/photos/chuchu/">chuchu</a> posted a photograph:<br />
<a href="http://www.zooomr.com/photos/chuchu/6556014/" class="image_link" ><img src="http://static.zooomr.com/images/6556014_00421b6456_m.jpg" alt="ギンガメアジとジンベイ" title="ギンガメアジとジンベイ" /></a><br />
</description>
<pubDate>Mon, 22 Dec 2008 04:14:52 +0000</pubDate>
<author zooomr:profile="http://www.zooomr.com/people/chuchu/">nobody@zooomr.com (chuchu)</author>
<guid isPermaLink="false">tag:zooomr.com,2004:/photo/6556014</guid>
<media:content url="http://static.zooomr.com/images/6556014_00421b6456_m.jpg" type="image/jpeg" />
<media:title>ギンガメアジとジンベイ</media:title>
<media:text type="html">
<a href="http://www.zooomr.com/photos/chuchu/">chuchu</a> posted a photograph:<br />
<a href="http://www.zooomr.com/photos/chuchu/6556014/" class="image_link" ><img src="http://static.zooomr.com/images/6556014_00421b6456_m.jpg" alt="ギンガメアジとジンベイ" title="ギンガメアジとジンベイ" /></a><br />
</media:text>
<media:thumbnail url="http://static.zooomr.com/images/6556014_00421b6456_s.jpg" height="75" width="75" />
<media:credit role="photographer">chuchu</media:credit>
<media:category scheme="urn:zooomr:tags">海遊館 aquarium kaiyukan osaka japan</media:category>
</item>
As you can see from the above XML snippets there is no consistency in how they represent photo streams. Even though both Picasa and Zoomr use Yahoo's Media RSS extensions, they generate different markup. Picasa has the media extensions as a set of elements within a media:group element that is a child of the item element while Zooomr simply places a grab bag of Media RSS elements such including media:thumbnail and media:content as children of the item element. Smugmug takes the cake by simply tunneling some escaped HTML in the atom:content element instead of using explicit metadata to describe the photos.
The bottom line is that it isn't possible to satisfy Dave Winer's request and create a level playing field today because there are no consistently applied standards for representing photo streams in RSS/Atom. This is unfortunate because it means that services have to write one off code (aka the beautiful fucking snowflake problem) for each photo sharing site they want to integrate with. Not only is this a lot of unnecessary code, it also prevents such integration from being a simple plug and play experience for users of social aggregation services.
So far, the closest thing to a standard in this space is Media RSS but as the name states it is an RSS based format and really doesn't fit with the Atom syndication format's data model. This is why Martin Atkins has started working on Atom Media Extensions which is an effort to create a similar set of media extensions for the Atom syndication format.
What I like about the first draft of Atom media extensions is that it is focused on the basic case of syndicating audio, video and image for use in activity streams and doesn't have some of the search related and feed republishing baggage you see in related formats like Media RSS or iTunes RSS extensions.
The interesting question is how to get the photo sites out there to adopt consistent standards in this space? Maybe we can get Google to add it to their Open Stack™ since they've been pretty good at getting social sites to adopt their standards and have been generally good at evangelization.
 Now Playing: DMX - Ruff Ryders' Anthem
Now Playing: DMX - Ruff Ryders' Anthem